
How do we inject capability to detect and tokenize phrases using Automatic Phrazing Token Filter in Fusion? Well below are the details on how to do it.
Configuration Settings:
1. Using this github create your jar. [https://github.com/lucidworks/auto-phrase-tokenfilter]. Copy JAR [“auto-phrase-tokenfilter-1.0.jar”] to solr
Location to copy JAR “/opt/fusion/<version>/apps/solr-dist/dist”
2. Update solr config.xml
Add lib reference
<lib dir="${solr.install.dir:../../../..}/dist/" regex="auto-phrase-tokenfilter.*\.jar" />
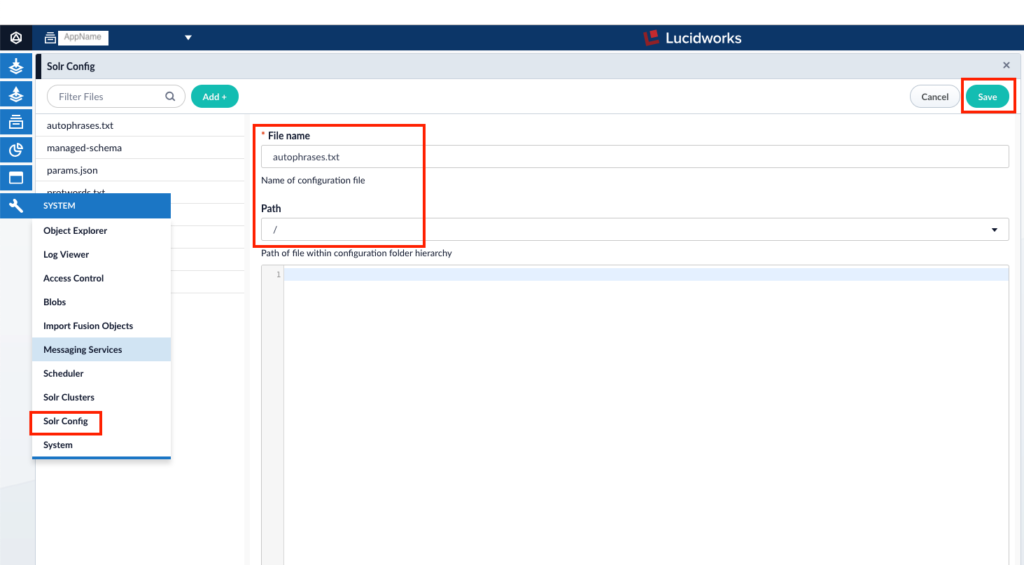
3. Add a new text file “autophrases.txt” to Solr Config
- Goto System –> Solr Config
- Enter Filename and keep default location for file in Path.
- Save the changes
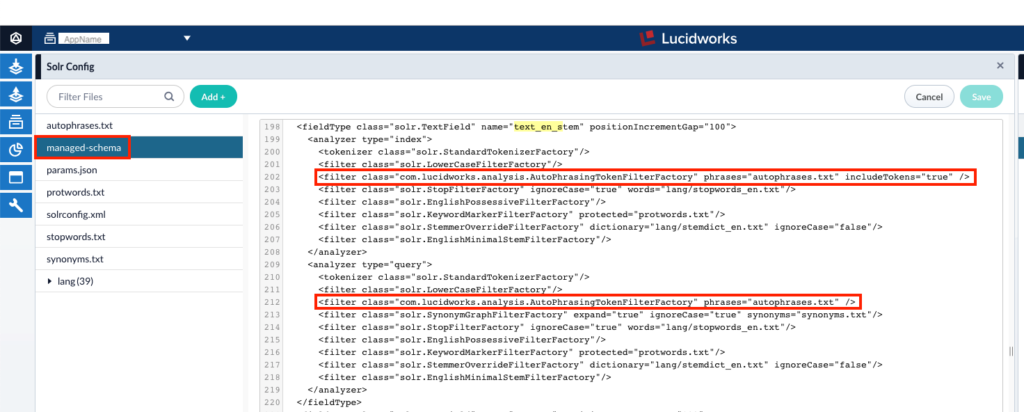
4. Add “AutoPhrasingTokenFilterFactory” filter to managed-schema
- Goto System –> Solr Config –> managed-schema
- Add below in index analyzer
<filter class="com.lucidworks.analysis.AutoPhrasingTokenFilterFactory" phrases="autophrases.txt" includeTokens="true" />
Add below in query analyzer to specific fieldType
<filter class="com.lucidworks.analysis.AutoPhrasingTokenFilterFactory" phrases="autophrases.txt" />
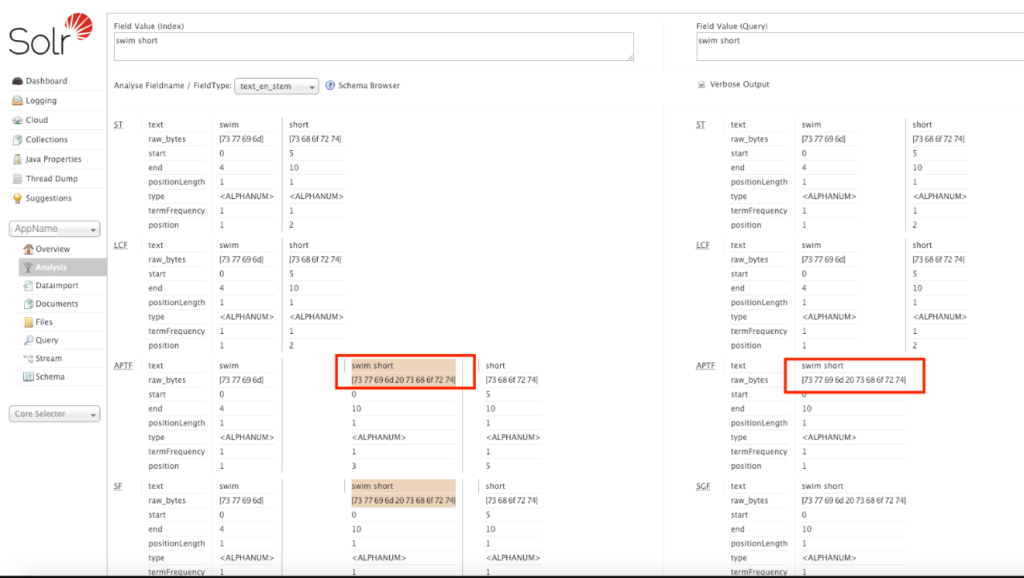
Example:
Add “swim short” to autophrases.txt and save the file.
And validate the change in Solr Admin

Have a different use case? Email why9@cirrus10.com

