Elasticsearch Basics
At the core of elasticsearch’s intelligent search engine is Lucene. It’s highly scalable, real-time search, distributed and analytics and is natively JSON + REST API. In this tutorial we’ll look at some components and features of Elasticsearch.
Cluster
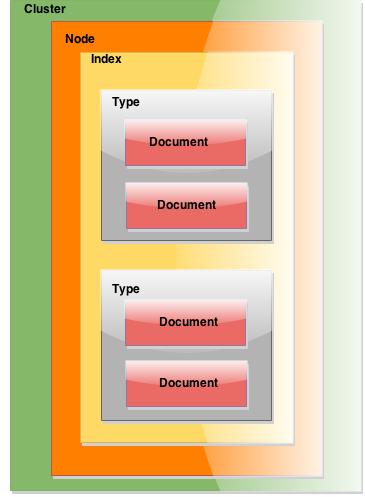
your entire data and provides
federated indexing and search
capabilities across all nodes.

Node
A node is a single server that is part of your cluster, stores your data, and participates in the cluster’s indexing and search capabilities.
Index
An index is a collection of documents that have somewhat similar characteristics.
Document
A document is a basic unit of information that can be indexed.
Type
A type is a logical category/partition of your index whose semantics is completely up to you.
| Elasticsearch Features |
| Real Time Data |
| Real Time Analytics |
| High Availability |
| Distributed |
| Full Text Search |
| RESTful API |
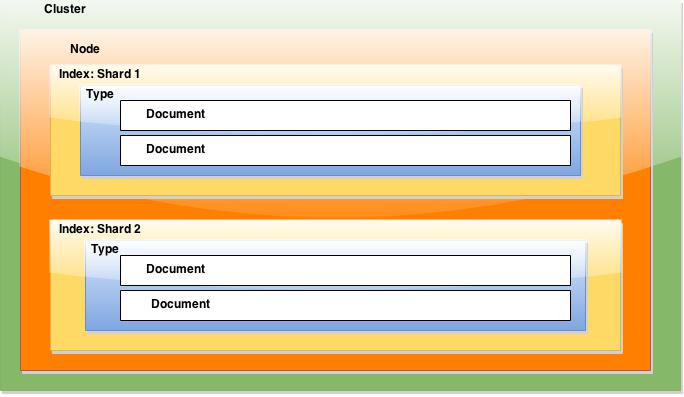
Elasticsearch can subdivide index into multiple pieces called shards.
Sharding is important for two primary reasons:
- Horizontally split/scale your content volume
- Distribute and parallelize operations across shards thus increasing performance/throughput
Real Time Data
Data flows into your system but getting in back real fast is what we are looking for.Need examples, OK Searching 50 millions venues in real time? Foursquare does it using Elasticsearch. Fog Creek Software’s search is control by Elasticsearch for 30 million requests per month across 40 billion lines of code and many more.
Real Time Analytics
Exploring data is as important as free text search today.Understanding data and gaining insights allows business to take better decision and improve product.
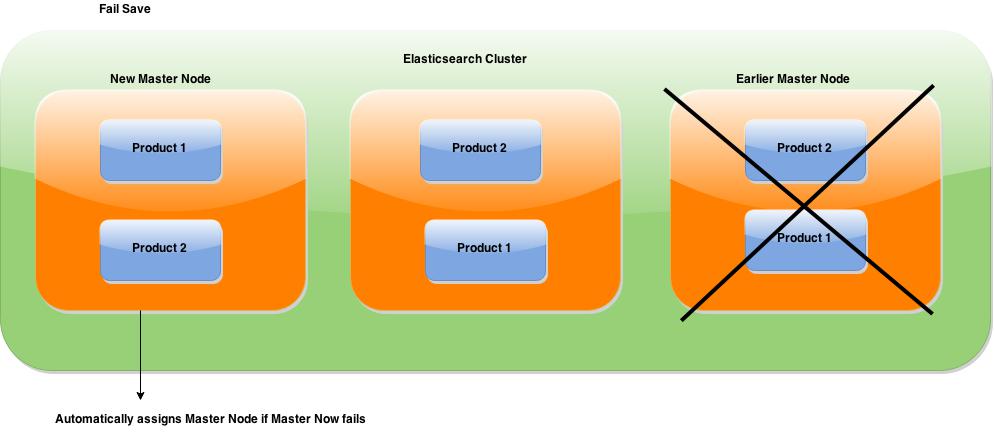
High Availability
Elasticsearch clusters are resilient — they will detect and remove failed nodes, and reorganize themselves to ensure that your data is safe and accessible.
Elasticsearch allows you to make one or more copies of your index’s shards into what are called replica shards, or replicas for short.
Replication is important for two primary reasons:
- High availability in case a shard/node fails. For this reason, it is important to note that a replica shard is never allocated on same node as original/primary shard that it was copied from.
- Scale out your search volume/throughput since searches can be executed on all replicas in parallel.
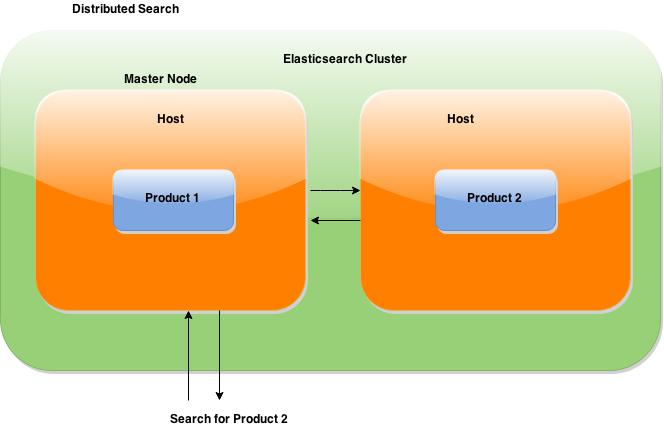
Distributed
Elasticsearch allows you to start small, but will grow with your business. It is built to scale horizontally out of the box. As you need more capacity, just add more nodes, and let the cluster reorganize itself to take advantage of the extra hardware.
Full Text Search
Using Lucene under the hood to provide powerful full text search capabilities available in any open source product. Search comes with multi-language support, a powerful query language, support for geolocation, context aware did-you-mean suggestions, autocomplete, search snippets and many more.
Comparison of DB and Elasticsearch
| DB | Elasticsearch |
| Database | Index or Indices |
| Table | Type |
| Column | Field |
Configurable and Extensible
ES configurations can be changed while ES is running, but some will require a restart (and in some cases reindexing). Most configurations can be changed using the REST API as well.
ES has several extension points – namely site plugins (let you serve static content from ES), rivers (for feeding data into ES), and plugins that let you add modules.
Elasticsearch Configuration Example [elasticsearch.yml]
Basic this which can be configured are
- cluster.name : Cluster name identifies your cluster for auto-discovery. If you’re running multiple clusters on the same network, make sure you’re using unique names.
- node.name : Node names are generated dynamically on startup, so you’re relieved from configuring them manually. You can tie this node to a specific name.
- node.master & node.data : Every node can be configured to allow or deny being eligible as the master, and to allow or deny to store the data. Master allow this node to be eligible as a master node (enabled by default) and Data allow this node to store data (enabled by default).
You can exploit these settings to design advanced cluster topologies.
- 1. You want this node to never become a master node, only to hold data. This will be the “workhorse” of your cluster. master: false, node.data: true
- 2. You want this node to only serve as a master: to not store any data and to have free resources. This will be the “coordinator” of your cluster. master: true, node.data: false
- 3. You want this node to be neither master nor data node, but to act as a “search load balancer” (fetching data from nodes, aggregating results, etc.) node.master: false, node.data: false
There are more advance settings for having control over you data & config.
Connect kubernetes pod to a GCS bucket using JS
To connect from a Kubernetes pod to a Google Cloud Storage (GCS)…Easiest way to run an LLM locally on your Mac
I recently sought an efficient method for local experimentation with Language Model…EKS cluster using an existing VPC
The eksctl command line tool can create a cluster by either command-line options or…kubectl Unable to connect to the server
When working with Kubernetes if you are getting Unable to conntect to…